The Meeting That Ends Before It Begins
In 2022, a Series B fintech company in London brought in an external development team that had stellar reviews, a polished portfolio, and references from three recognisable enterprise clients. 11 months later, the CTO — a quiet Scot named David Brennan — terminated the contract mid-sprint.
The team hadn’t delivered bad code. The features worked. The problem was something Brennan struggled to articulate in the exit meeting. “I never knew who owned anything,” he said later. “Every bug lived in a grey zone. Every release felt like a gamble. And when something broke at night, the question was always — who do we call?”
This story isn’t unusual.
Enterprise CTOs are making hiring decisions about external dev teams every week. And the criteria they actually use — the real, unwritten checklist — is almost never the one vendors are preparing for. Not the technical stack. Not the team size. Not the portfolio of logos.
It’s 5 other things. And if your team can’t answer them cleanly, no amount of case studies will save the engagement.
“We ‘ve sat through hundreds of vendor pitches. The ones that lose my confidence all have the same tell — they haven’t thought about what happens when something goes wrong.” — Anonymous CTO, enterprise SaaS, £200M ARR

Signal One: How Your Team Handles a Bug at Midnight
Every external dev team claims they have processes. Very few have a protocol — a documented, rehearsed, human-assigned chain of response for when production breaks at an inconvenient hour.
The difference matters more than people realise. A process is a flowchart on a wiki page. A protocol is a phone number attached to a name, attached to a decision-making authority, attached to an SLA that someone has agreed to own.
Consider what happens in almost every major enterprise outage that involves multiple vendors: the technical fix is rarely the hard part. The hard part is the first 20 minutes — when three teams are on a call, each assuming one of the others has the lead, and nobody does. Incident timelines consistently show that the longest gap isn’t between “problem detected” and “fix deployed.” It’s between “problem detected” and “someone takes ownership.”
Experienced CTOs have usually lived through at least one version of this. They’re not asking about your debugging skills. They’re asking: when something breaks in production, who is the single human being responsible for bringing it back up — and do they have the authority to make decisions without a nine-hour approval chain?
If your answer is “we have a ticketing system and an on-call rotation,” that’s a process. If your answer is “Sarah Chen is your named incident lead, her number is in your Slack, and here is the documented response runbook we’ve already built for your environment” — that’s a protocol.
That distinction determines whether a CTO sleeps at night.
Pain Point Addressed: Bugs & Downtime
The question behind the question: “If something breaks badly — not a minor bug, but a full production outage — do I know exactly who is responsible, how fast they’ll respond, and what authority they have to act?” If your team hasn’t mapped this clearly before the first sprint, you’ve already lost trust you don’t know you’ve lost.
Signal Two: Release Cadence That Tells a Story
There are two types of external dev teams. The ones that ship small, the ones that ship big. And enterprise CTOs — particularly those who have been through a digital transformation or two — have learned to be deeply suspicious of teams that ship big.
“Big releases are where trust goes to die,” one CTO told us, speaking about a vendor engagement that ended badly at a major UK retailer. “They’d been working for 12 weeks. One day they pushed everything to staging. 2 thousand changed files. Nobody had any idea what was in there except them.”
Slow releases — the kind where a team gathers 3 months of work into one enormous deployment — are not just a technical risk. They’re a signal about how a team thinks about risk. About whether they’ve built the kind of internal CI/CD maturity that makes frequent, safe releases possible. About whether they’re optimising for their own comfort or for the client’s peace of mind.
The teams that win enterprise contracts in 2025 are the ones that can demonstrate a deployment history. Not a list of features. A history — timestamped, measurable — of how often they shipped, how large those changes were, what their rollback rate was, and how long it took to recover when a release needed to be unwound.
Netflix famously deploys to production hundreds of times per day. That’s an extreme example. But the underlying philosophy — small batches, fast feedback, high confidence — is exactly what a seasoned CTO is looking for evidence of when they’re reviewing a potential vendor.
If your team’s strongest argument for release quality is “we test thoroughly before we ship” — that’s not enough. That’s table stakes. The question is: what does your deployment trail look like? And does it suggest a team that treats every release as a calculated, contained event — or a team that treats release day like a gamble?
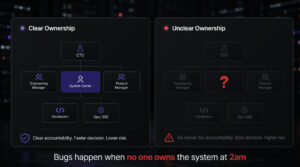
Signal Three: The Ownership Map (The One Nobody Brings)
Of all the documents an external dev teams could bring to an initial engagement, the one that creates the most immediate credibility with enterprise CTOs is one almost no team ever brings: an ownership map.
Not a RACI. Not an org chart. An ownership map.
The difference is important. A RACI tells you who is responsible, accountable, consulted, and informed on a project. An ownership map tells you something more specific: for each component of the system your team builds or touches, who is the named human being responsible for its health, its incidents, its technical debt backlog, and its long-term evolution?
When Spotify scaled its engineering organisation in the early 2010s, it introduced the squad model partly to solve exactly this problem — not just to organise teams, but to ensure every service had a squad that owned it end-to-end. The goal wasn’t efficiency. The goal was accountability. Someone had to care about every corner of the system.
External dev teams, almost by definition, resist full ownership. The engagement is time-bounded. The team rotates. The codebase eventually gets handed back. This structural reality creates a predictable cultural pattern: nobody owns the harder problems, because those problems will outlast the contract.
The CTOs who’ve been burned know this. They’re listening — very carefully — for how a vendor talks about ownership. Whether they use vague collective language (“the team will handle it”) or precise individual language (“Marcus is the service owner for the payments module; here’s how to reach him and what that ownership means in practice”).
The ownership map is the document that says: we’ve already thought about this. You don’t have to worry about it.
“Nobody brings an ownership map. Nobody. The one team that did, I hired them before the meeting was over.” — VP Engineering, Enterprise Platform, North America
Signal Four: The Risky Update Conversation
Every meaningful codebase eventually needs a risky update — a security patch to a deeply embedded dependency, a database migration on a live system, a breaking API change that touches four downstream services. These are the moments where a team’s engineering culture becomes visible.
Enterprise CTOs ask about risky updates not because they want to stress-test vendors, but because the conversation reveals something that portfolios and proposals never do: how does this team actually reason about risk?
The bad answer to “walk through how you’d handle a risky update” sounds like confidence. It lists steps. It mentions testing environments. It ends with something about rollback plans.
The good answer sounds like humility. It starts with “the first thing we do is decide whether this update is actually necessary right now” — which is a risk management instinct, not a technical instinct. It talks about communication: who gets told, when, in what format. It mentions that whoever owns the risky update also owns the post-update monitoring window, by name, not by role.
In 2021, a widely-used npm package called ua-parser-js was compromised, injecting malware into thousands of downstream projects. The teams that identified and resolved the issue fastest weren’t the most technically sophisticated. They were the ones with clear ownership protocols and internal communication channels that could move a decision from “we have a problem” to “we have a plan” in under an hour.
The external dev teams that win long-term enterprise relationships are the ones that treat risky updates as a communication problem first, and a technical problem second.
Pain Point Addressed: Risky Updates
What to prepare: Document your team’s last three genuinely risky updates. What was the risk? Who made the call to proceed? How was the client informed? What did the post-update monitoring look like? This document — concrete, unglamorous, honest — tells a CTO more about your team than a hundred testimonials.
Signal Five: Who Owns It When Nobody Is Watching
The final signal is the hardest to fake, which is why it’s the most valuable to demonstrate.
There’s a specific type of engagement failure that enterprise CTOs dread — the one where the external team is technically competent, the code is clean, the features ship, and yet somehow, six months in, nobody quite knows the health of the system. There’s technical debt accumulating in corners nobody inspects. There are dependencies that haven’t been updated. There are monitoring gaps that haven’t been flagged.
This isn’t malice. It’s gravity. External dev teams drift toward the work that’s visible, measurable, and billable. The invisible work — the system hygiene, the dependency audits, the proactive monitoring reviews — tends to fall into the gap between what was explicitly specified in the contract and what good engineering actually requires.
The phrase “nobody owns it” is the quiet ending of more enterprise vendor relationships than any missed deadline or botched launch. It’s the creeping realisation that the team is good at building, but not at stewarding.
What CTOs are looking for — and almost never receive unprompted — is evidence that the external team has a self-initiated rhythm of invisible work. Not just the work that’s on the sprint board. The work that exists because the system deserves it, not because a ticket was raised.
Some of the best vendor teams in this space have a simple practice: a monthly system health note, sent to the client’s CTO, covering dependency status, monitoring anomalies, technical debt flags, and security considerations. Not as a deliverable. Not as a line item. Just as evidence that someone cares about the system even when no one is watching.
That practice — small, consistent, unglamorous — is worth more to an enterprise CTO than ten feature launches.

What Winning Teams Do Differently
The external dev teams that build long-term enterprise relationships — the ones that get renewed, expanded, and referred — are not necessarily the most technically talented. They’re the ones who’ve understood that the CTO’s real fears aren’t technical.
They’re operational. They’re relational. They’re about sleep and trust and the confidence that someone else has thought carefully about what happens when things go sideways.
Before your next enterprise pitch, ask your team these five questions:
- Who is the named incident lead for this client’s environment, and can we give the CTO their phone number on day one?
- What does our deployment history actually show — and would a CTO reading it feel comfortable or nervous?
- Can we produce an ownership map for every component we’ll touch before the first sprint ends?
- What’s the last risky update we handled, and would we be comfortable walking a CTO through every decision we made?
- What is the uninstructed work we do — the system care that isn’t in a ticket — and can we show evidence of it?
If your team can answer all questions with specifics, not generalities, you’re not competing on the same terms as everyone else. You’re competing at a different level.
That’s where enterprise relationships are won.
Reference :
- ua-parser-js npm compromise (2021): CISA Official Alert
- Rapid7 Blog
- GitHub Issue Thread (developer’s own disclosure)
- Help Net Security
- Spotify Squad Model (2012): Original Whitepaper by Kniberg & Ivarsson
- Ideaplan Case Study
- Netflix Deployment Frequency: Netflix Tech Blog (official)
- InfoQ QCon 2013 Coverage
- Talent500 Netflix Architecture

Faheem Hasan
Brings over 12+ years of specialized experience in web and Laravel application development, backed by a proven 99.9% reliability record across enterprise-grade environments. As a driving force behind Laracore’s vision, he leads with precision and innovation—delivering robust, high-performance Laravel maintenance and development solutions that meet the highest global standards.


